Get Started#
Installation#
Fairlearn can be installed with pip from
PyPI as follows:
pip install fairlearn
Fairlearn is also available on conda-forge:
conda install -c conda-forge fairlearn
For further information on how to install Fairlearn and its optional dependencies, please check out the Installation Guide.
If you are updating from a previous version of Fairlearn, please see Version guide.
Note
The Fairlearn API is still evolving, so example code in
this documentation may not work with every version of Fairlearn.
Please use the version selector to get to the instructions for
the appropriate version. The instructions for the main
branch require Fairlearn to be installed from a clone of the
repository.
Overview of Fairlearn#
The Fairlearn package has two components:
Metrics for assessing which groups are negatively impacted by a model, and for comparing multiple models in terms of various fairness and accuracy metrics.
Algorithms for mitigating unfairness in a variety of AI tasks and along a variety of fairness definitions.
Fairlearn in 10 minutes#
The Fairlearn toolkit can assist in assessing and mitigation unfairness in Machine Learning models. It’s impossible to provide a sufficient overview of fairness in ML in this Quickstart tutorial, so we highly recommend starting with our User Guide. Fairness is a fundamentally sociotechnical challenge and cannot be solved with technical tools alone. They may be helpful for certain tasks such as assessing unfairness through various metrics, or to mitigate observed unfairness when training a model. Additionally, fairness has different definitions in different contexts and it may not be possible to represent it quantitatively at all.
Given these considerations this Quickstart tutorial merely provides short code snippet examples of how to use basic Fairlearn functionality for those who are already intimately familiar with fairness in ML. The example below is about binary classification, but we similarly support regression.
Prerequisites#
In order to run the code samples in the Quickstart tutorial, you need to install the following dependencies:
pip install fairlearn matplotlib
Loading the dataset#
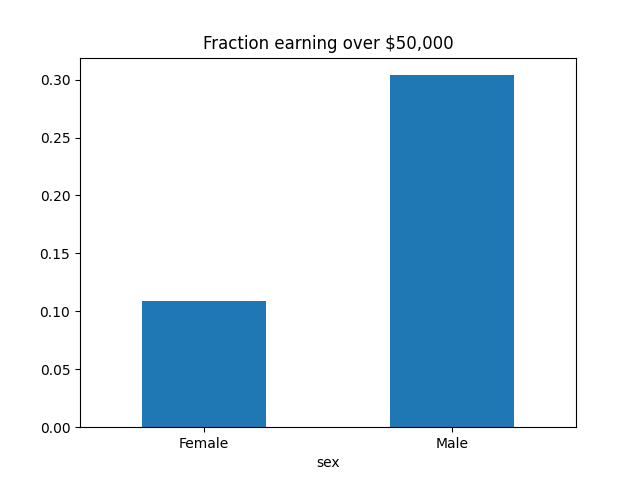
For this example we use the UCI adult dataset where the objective is to predict whether a person makes more (label 1) or less (0) than $50,000 a year.
>>> import numpy as np
>>> import pandas as pd
>>> import matplotlib.pyplot as plt
>>> from fairlearn.datasets import fetch_adult
>>> data = fetch_adult(as_frame=True)
>>> X = pd.get_dummies(data.data)
>>> y_true = (data.target == '>50K') * 1
>>> sex = data.data['sex']
>>> sex.value_counts()
sex
Male 32650
Female 16192
Name: count, dtype: int64
Evaluating fairness-related metrics#
Firstly, Fairlearn provides fairness-related metrics that can be compared between groups and for the overall population. Using existing metric definitions from scikit-learn we can evaluate metrics for subgroups within the data as below:
>>> from fairlearn.metrics import MetricFrame
>>> from sklearn.metrics import accuracy_score
>>> from sklearn.tree import DecisionTreeClassifier
>>>
>>> classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4)
>>> classifier.fit(X, y_true)
DecisionTreeClassifier(...)
>>> y_pred = classifier.predict(X)
>>> mf = MetricFrame(metrics=accuracy_score, y_true=y_true, y_pred=y_pred, sensitive_features=sex)
>>> mf.overall
0.8443...
>>> mf.by_group
sex
Female 0.9251...
Male 0.8042...
Name: accuracy_score, dtype: float64
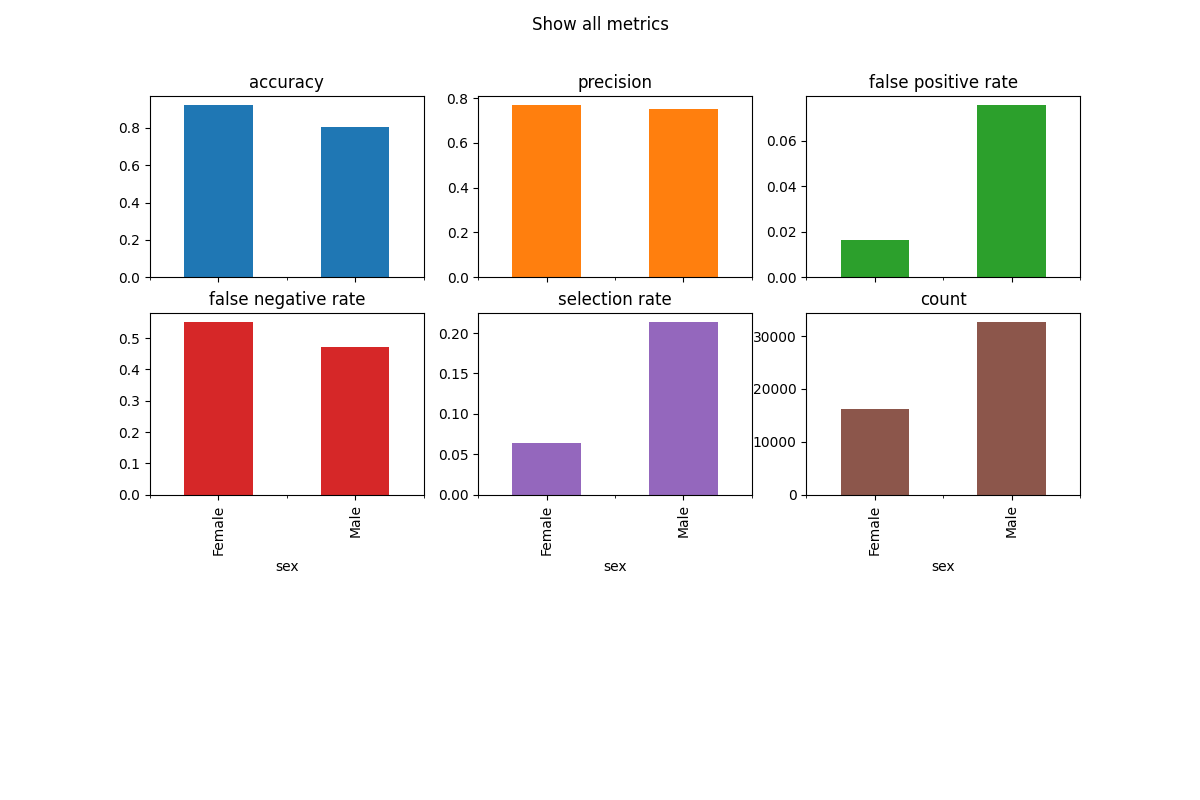
Additionally, Fairlearn has lots of other standard metrics built-in, such as selection rate, i.e., the percentage of the population which have ‘1’ as their label:
>>> from fairlearn.metrics import selection_rate
>>> sr = MetricFrame(metrics=selection_rate, y_true=y_true, y_pred=y_pred, sensitive_features=sex)
>>> sr.overall
0.1638...
>>> sr.by_group
sex
Female 0.0635...
Male 0.2135...
Name: selection_rate, dtype: float64
Fairlearn also allows us to quickly plot these metrics from the
fairlearn.metrics.MetricFrame
metrics = {
"accuracy": accuracy_score,
"precision": precision_score,
"false positive rate": false_positive_rate,
"false negative rate": false_negative_rate,
"selection rate": selection_rate,
"count": count,
}
metric_frame = MetricFrame(
metrics=metrics, y_true=y_true, y_pred=y_pred, sensitive_features=sex
)
metric_frame.by_group.plot.bar(
subplots=True,
layout=[3, 3],
legend=False,
figsize=[12, 8],
title="Show all metrics",
)
Mitigating disparity#
If we observe disparities between groups we may want to create a new model while specifying an appropriate fairness constraint. Note that the choice of fairness constraints is crucial for the resulting model, and varies based on application context. If selection rate is highly relevant for fairness in this contrived example, we can attempt to mitigate the observed disparity using the corresponding fairness constraint called Demographic Parity. In real world applications we need to be mindful of the sociotechnical context when making such decisions. The Exponentiated Gradient mitigation technique used fits the provided classifier using Demographic Parity as the objective, leading to a vastly reduced difference in selection rate:
>>> from fairlearn.reductions import DemographicParity, ExponentiatedGradient
>>> np.random.seed(0) # set seed for consistent results with ExponentiatedGradient
>>>
>>> constraint = DemographicParity()
>>> classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4)
>>> mitigator = ExponentiatedGradient(classifier, constraint)
>>> mitigator.fit(X, y_true, sensitive_features=sex)
ExponentiatedGradient(...)
>>> y_pred_mitigated = mitigator.predict(X)
>>>
>>> sr_mitigated = MetricFrame(metrics=selection_rate, y_true=y_true, y_pred=y_pred_mitigated, sensitive_features=sex)
>>> sr_mitigated.overall
0.1661...
>>> sr_mitigated.by_group
sex
Female 0.1552...
Male 0.1715...
Name: selection_rate, dtype: float64
What’s next?#
Please refer to our User Guide for a comprehensive view on Fairness in Machine Learning and how Fairlearn fits in, as well as an exhaustive guide on all parts of the toolkit. For concrete examples check out the Example Notebooks section. Finally, we also have a collection of Frequently asked questions.