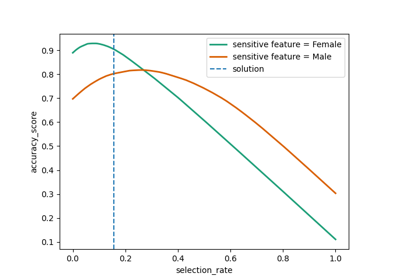
fairlearn.postprocessing.ThresholdOptimizer#
- class fairlearn.postprocessing.ThresholdOptimizer(*, estimator=None, constraints='demographic_parity', objective='accuracy_score', grid_size=1000, flip=False, prefit=False, predict_method='auto')[source]#
A classifier based on the threshold optimization approach.
The classifier is obtained by applying group-specific thresholds to the provided estimator. The thresholds are chosen to optimize the provided performance objective subject to the provided fairness constraints.
Read more in the User Guide.
- Parameters:
- estimatorobject
A scikit-learn compatible estimator whose output is postprocessed.
- constraintsstr, default=’demographic_parity’
Fairness constraints under which threshold optimization is performed. Possible inputs are:
- ‘demographic_parity’, ‘selection_rate_parity’ (synonymous)
match the selection rate across groups
- ‘{false,true}_{positive,negative}_rate_parity’
match the named metric across groups
- ‘equalized_odds’
match true positive and false positive rates across groups
- objectivestr, default=’accuracy_score’
Performance objective under which threshold optimization is performed. Not all objectives are allowed for all types of constraints. Possible inputs are:
- ‘accuracy_score’, ‘balanced_accuracy_score’
allowed for all constraint types
- ‘selection_rate’, ‘true_positive_rate’, ‘true_negative_rate’,
allowed for all constraint types except ‘equalized_odds’
- grid_sizeint, default=1000
The values of the constraint metric are discretized according to the grid of the specified size over the interval [0,1] and the optimization is performed with respect to the constraints achieving those values. In case of ‘equalized_odds’ the constraint metric is the false positive rate.
- flipbool, default=False
If True, then allow flipping the decision if it improves the resulting
- prefitbool, default=False
If True, avoid refitting the given estimator. Note that when used with
sklearn.model_selection.cross_val_score(),sklearn.model_selection.GridSearchCV, this will result in an error. In that case, please useprefit=False.- predict_method{‘auto’, ‘predict_proba’, ‘decision_function’, ‘predict’ }, default=’auto’
Defines which method of the
estimatoris used to get the output values.- ‘auto’
use one of
predict_proba,decision_function, orpredict, in that order.- ‘predict_proba’
use the second column from the output of
predict_proba. It is assumed that the second column represents the positive outcome.- ‘decision_function’
use the raw values given by the
decision_function.- ‘predict’
use the hard values reported by the
predictmethod if estimator is a classifier, and the regression values if estimator is a regressor. This is equivalent to what is done in [1].
New in version 0.7: In previous versions only the
predictmethod was used implicitly.Changed in version 0.7: From version 0.7, ‘predict’ is deprecated as the default value and the default changes to ‘auto’ from v0.10.
Notes
The procedure is based on the algorithm of Hardt et al. [1].
References
Examples
>>> from fairlearn.postprocessing import ThresholdOptimizer >>> from sklearn.linear_model import LogisticRegression >>> X = [[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]] >>> y = [ 1 , 1 , 1 , 1 , 0, 0 , 1 , 0 , 0 , 0 ] >>> sensitive_features = ["a", "b", "a", "a", "b", "a", "b", "b", "a", "b"] >>> unmitigated_lr = LogisticRegression().fit(X, y) >>> postprocess_est = ThresholdOptimizer( ... estimator=unmitigated_lr, ... constraints="false_negative_rate_parity", ... objective="balanced_accuracy_score", ... prefit=True, ... predict_method='predict_proba') >>> postprocess_est.fit(X, y, sensitive_features=sensitive_features) ThresholdOptimizer(constraints='false_negative_rate_parity', estimator=LogisticRegression(), objective='balanced_accuracy_score', predict_method='predict_proba', prefit=True)
- fit(X, y, *, sensitive_features, **kwargs)[source]#
Fit the model.
The fit is based on training features and labels, sensitive features, as well as the fairness-unaware predictor or estimator. If an estimator was passed in the constructor this fit method will call fit(X, y, **kwargs) on said estimator.
- Parameters:
- Xnumpy.ndarray or pandas.DataFrame
The feature matrix
- ynumpy.ndarray, pandas.DataFrame, pandas.Series, or list
The label vector
- sensitive_featuresnumpy.ndarray, list, pandas.DataFrame, or pandas.Series
sensitive features to identify groups by
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict(X, *, sensitive_features, random_state=None)[source]#
Predict label for each sample in X while taking into account sensitive features.
- Parameters:
- Xnumpy.ndarray or pandas.DataFrame
feature matrix
- sensitive_featuresnumpy.ndarray, list, pandas.DataFrame, pandas.Series
sensitive features to identify groups by
- random_stateint or
numpy.random.RandomStateinstance, default=None Controls random numbers used for randomized predictions. Pass an int for reproducible output across multiple function calls.
- Returns:
- numpy.ndarray
The prediction in the form of a scalar or vector. If X represents the data for a single example the result will be a scalar. Otherwise the result will be a vector.
- set_fit_request(*, sensitive_features: bool | None | str = '$UNCHANGED$') ThresholdOptimizer[source]#
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sensitive_featuresstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sensitive_featuresparameter infit.
- Returns:
- selfobject
The updated object.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_predict_request(*, random_state: bool | None | str = '$UNCHANGED$', sensitive_features: bool | None | str = '$UNCHANGED$') ThresholdOptimizer[source]#
Request metadata passed to the
predictmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- random_statestr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
random_stateparameter inpredict.- sensitive_featuresstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sensitive_featuresparameter inpredict.
- Returns:
- selfobject
The updated object.