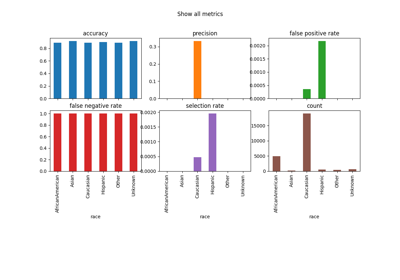
fairlearn.metrics.MetricFrame#
- class fairlearn.metrics.MetricFrame(*, metrics, y_true, y_pred, sensitive_features, control_features=None, sample_params=None, n_boot=None, ci_quantiles=None, random_state=None)[source]#
Collection of disaggregated metric values.
This data structure stores and manipulates disaggregated values for any number of underlying metrics. At least one sensitive feature must be supplied, which is used to split the data into subgroups. The underlying metric(s) is(are) calculated across the entire dataset (made available by the
overallproperty) and for each identified subgroup (made available by theby_groupproperty).The only limitations placed on the metric functions are that:
The first two arguments they take must be
y_trueandy_predarraysAny other arguments must correspond to sample properties (such as sample weights), meaning that their first dimension is the same as that of y_true and y_pred. These arguments will be split up along with the
y_trueandy_predarrays
The interpretation of the
y_trueandy_predarrays is up to the underlying metric - it is perfectly possible to pass in lists of class probability tuples. We also support non-scalar return types for the metric function (such as confusion matrices) at the current time. However, the aggregation functions will not be well defined in this case.Group fairness metrics are obtained by methods that implement various aggregators over group-level metrics, such as the maximum, minimum, or the worst-case difference or ratio.
This data structure also supports the concept of ‘control features.’ Like the sensitive features, control features identify subgroups within the data, but aggregations are not performed over the control features. Instead, the aggregations produce a result for each subgroup identified by the control feature(s). The name ‘control features’ refers to the statistical practice of ‘controlling’ for a variable.
Read more in the User Guide.
Added in version 0.5.0.
Changed in version 0.7.0: The
metricargument was renamed tometricsand constructor arguments became keyword-only.- Parameters:
- metrics
callable()ordict The underlying metric functions which are to be calculated. This can either be a single metric function or a dictionary of functions. These functions must be callable as
fn(y_true, y_pred, **sample_params). If there are any other arguments required (such asbetaforsklearn.metrics.fbeta_score()) thenfunctools.partial()must be used.Note that the values returned by various members of the class change based on whether this argument is a callable or a dictionary of callables. This distinction remains even if the dictionary only contains a single entry.
- y_true
list,pandas.Series,numpy.ndarray,pandas.DataFrame The ground-truth labels (for classification) or target values (for regression).
- y_pred
list,pandas.Series,numpy.ndarray,pandas.DataFrame The predictions.
- sensitive_features
list,pandas.Series,dictof 1d arrays,numpy.ndarray,pandas.DataFrame The sensitive features which should be used to create the subgroups. At least one sensitive feature must be provided. All names (whether on pandas objects or dictionary keys) must be strings. We also forbid DataFrames with column names of
None. For cases where no names are provided we generate namessensitive_feature_[n].- control_features
list,pandas.Series,dictof 1d arrays,numpy.ndarray,pandas.DataFrame Control features are similar to sensitive features, in that they divide the input data into subgroups. Unlike the sensitive features, aggregations are not performed across the control features - for example, the
overallproperty will have one value for each subgroup in the control feature(s), rather than a single value for the entire data set. Control features can be specified similarly to the sensitive features. However, their default names (if none can be identified in the input values) are of the formatcontrol_feature_[n]. See the section on intersecting groups in the User Guide to learn how to use control levels.Note the types returned by members of the class vary based on whether control features are present.
- sample_params
dict Parameters for the metric function(s). If there is only one metric function, then this is a dictionary of strings and array-like objects, which are split alongside the
y_trueandy_predarrays, and passed to the metric function. If there are multiple metric functions (passed as a dictionary), then this is a nested dictionary, with the first set of string keys identifying the metric function name, with the values being the string-to-array-like dictionaries.- n_boot
int|None If set to a positive integer, generate this number of bootstrap samples of the supplied data, and use to estimate confidence intervals for all of the metrics. Must be set with ci_quantiles.
- ci_quantiles
list[float] |None A list of confidence interval quantiles to extract from the bootstrap samples. For example, the list [0.159, 0.5, 0.841] would extract the median and standard deviations.
- random_state
int|np.random.RandomState|None Used to control the generation of the bootstrap samples
- metrics
Examples
We will now go through some simple examples (see the User Guide for a more in-depth discussion):
>>> from fairlearn.metrics import MetricFrame, selection_rate >>> from sklearn.metrics import accuracy_score >>> import pandas as pd >>> y_true = [1,1,1,1,1,0,0,1,1,0] >>> y_pred = [0,1,1,1,1,0,0,0,1,1] >>> sex = ['Female']*5 + ['Male']*5 >>> metrics = {"selection_rate": selection_rate} >>> mf1 = MetricFrame( ... metrics=metrics, ... y_true=y_true, ... y_pred=y_pred, ... sensitive_features=sex)
Access the disaggregated metrics via a pandas Series
>>> mf1.by_group selection_rate sensitive_feature_0 Female 0.8 Male 0.4
Access the largest difference, smallest ratio, and worst case performance
>>> print(f"difference: {mf1.difference().iloc[0]:.3} " ... f"ratio: {mf1.ratio().iloc[0]:.3} " ... f"max across groups: {mf1.group_max().iloc[0]:.3}") difference: 0.4 ratio: 0.5 max across groups: 0.8
You can also evaluate multiple metrics by providing a dictionary
>>> metrics_dict = {"accuracy":accuracy_score, "selection_rate": selection_rate} >>> mf2 = MetricFrame( ... metrics=metrics_dict, ... y_true=y_true, ... y_pred=y_pred, ... sensitive_features=sex)
Access the disaggregated metrics via a pandas DataFrame
>>> mf2.by_group accuracy selection_rate sensitive_feature_0 Female 0.8 0.8 Male 0.6 0.4
The largest difference, smallest ratio, and the maximum and minimum values across the groups are then all pandas Series, for example:
>>> mf2.difference() accuracy 0.2 selection_rate 0.4 dtype: float64
You’ll probably want to view them transposed
>>> pd.DataFrame({'difference': mf2.difference(), ... 'ratio': mf2.ratio(), ... 'group_min': mf2.group_min(), ... 'group_max': mf2.group_max()}).T accuracy selection_rate difference 0.20 0.4 ratio 0.75 0.5 group_min 0.60 0.4 group_max 0.80 0.8
More information about plotting metrics can be found in the plotting section of the User Guide.
- difference(method='between_groups', errors='coerce')[source]#
Return the maximum absolute difference between groups for each metric.
This method calculates a scalar value for each underlying metric by finding the maximum absolute difference between the entries in each combination of sensitive features in the
by_groupproperty.Similar to other methods, the result type varies with the specification of the metric functions, and whether control features are present or not.
There are two allowed values for the
method=parameter. The valuebetween_groupscomputes the maximum difference between any two pairs of groups in theby_groupproperty (i.e.group_max() - group_min()). Alternatively,to_overallcomputes the difference between each subgroup and the corresponding value fromoverall(if there are control features, thenoverallis multivalued for each metric). The result is the absolute maximum of these values.Read more in the User Guide.
- Return type:
- Parameters:
- method
str{‘between_groups’, ‘to_overall’}, defaultbetween_groups How to compute the aggregate.
- errors{‘raise’, ‘coerce’}, default
coerce if ‘raise’, then invalid parsing will raise an exception if ‘coerce’, then invalid parsing will be set as NaN
- method
- Returns:
- typing.Any or
pandas.Seriesorpandas.DataFrame The exact type follows the table in
MetricFrame.overall.
- typing.Any or
- difference_ci(method='between_groups')[source]#
Return the bootstrapped confidence intervals for
MetricFrame.difference().When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list, with each element having the same type as that returned by the
MetricFrame.difference()function. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.Unlike
MetricFrame.difference()there is noerrorsparameter, because a bootstrappedMetricFramerequires all the metrics to return scalars.
- group_max(errors='raise')[source]#
Return the maximum value of the metric over the sensitive features.
This method computes the maximum value over all combinations of sensitive features for each underlying metric function in the
by_groupproperty (it will only succeed if all the underlying metric functions return scalar values). The exact return type depends on whether control features are present, and whether the metric functions were specified as a single callable or a dictionary.Read more in the User Guide.
- Return type:
- Parameters:
- errors{‘raise’, ‘coerce’}, default
raise if ‘raise’, then invalid parsing will raise an exception if ‘coerce’, then invalid parsing will be set as NaN
- errors{‘raise’, ‘coerce’}, default
- Returns:
- typing.Any or
pandas.Seriesorpandas.DataFrame The maximum value over sensitive features. The exact type follows the table in
MetricFrame.overall.
- typing.Any or
- group_max_ci()[source]#
Return the bootstrapped confidence intervals for
MetricFrame.group_max.When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list, with each element having the same type as that returned by the
MetricFrame.group_max()function. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.Unlike
MetricFrame.group_max()there is noerrorsparameter, because a bootstrappedMetricFramerequires all the metrics to return scalars.
- group_min(errors='raise')[source]#
Return the minimum value of the metric over the sensitive features.
This method computes the minimum value over all combinations of sensitive features for each underlying metric function in the
by_groupproperty (it will only succeed if all the underlying metric functions return scalar values). The exact return type depends on whether control features are present, and whether the metric functions were specified as a single callable or a dictionary.Read more in the User Guide.
- Return type:
- Parameters:
- errors{‘raise’, ‘coerce’}, default
raise if ‘raise’, then invalid parsing will raise an exception if ‘coerce’, then invalid parsing will be set as NaN
- errors{‘raise’, ‘coerce’}, default
- Returns:
- typing.Any or
pandas.Seriesorpandas.DataFrame The minimum value over sensitive features. The exact type follows the table in
MetricFrame.overall.
- typing.Any or
- group_min_ci()[source]#
Return the bootstrapped confidence intervals for
MetricFrame.group_min.When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list, with each element having the same type as that returned by the
MetricFrame.group_min()function. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.Unlike
MetricFrame.group_min()there is noerrorsparameter, because a bootstrappedMetricFramerequires all the metrics to return scalars.
- ratio(method='between_groups', errors='coerce')[source]#
Return the minimum ratio between groups for each metric.
This method calculates a scalar value for each underlying metric by finding the minimum ratio (that is, the ratio is forced to be less than unity) between the entries in each column of the
by_groupproperty.Similar to other methods, the result type varies with the specification of the metric functions, and whether control features are present or not.
There are two allowed values for the
method=parameter. The valuebetween_groupscomputes the minimum ratio between any two pairs of groups in theby_groupproperty (i.e.group_min() / group_max()). Alternatively,to_overallcomputes the ratio between each subgroup and the corresponding value fromoverall(if there are control features, thenoverallis multivalued for each metric), expressing the ratio as a number less than 1. The result is the minimum of these values.Read more in the User Guide.
- Return type:
- Parameters:
- method
str{‘between_groups’, ‘to_overall’}, defaultbetween_groups How to compute the aggregate.
- errors{‘raise’, ‘coerce’}, default
coerce if ‘raise’, then invalid parsing will raise an exception if ‘coerce’, then invalid parsing will be set as NaN
- method
- Returns:
- typing.Any or
pandas.Seriesorpandas.DataFrame The exact type follows the table in
MetricFrame.overall.
- typing.Any or
- ratio_ci(method='between_groups')[source]#
Return the bootstrapped confidence intervals for
MetricFrame.ratio().When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list, with each element having the same type as that returned by the
MetricFrame.ratio()function. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.Unlike
MetricFrame.ratio()there is noerrorsparameter, because a bootstrappedMetricFramerequires all the metrics to return scalars.
- property by_group: Series | DataFrame#
Return the collection of metrics evaluated for each subgroup.
The collection is defined by the combination of classes in the sensitive and control features. The exact type depends on the specification of the metric function.
Read more in the User Guide.
- Returns:
pandas.Seriesorpandas.DataFrameWhen a callable is supplied to the constructor, the result is a
pandas.Series, indexed by the combinations of subgroups in the sensitive and control features.When the metric functions were specified with a dictionary (even if the dictionary only has a single entry), then the result is a
pandas.DataFramewith columns named after the metric functions, and rows indexed by the combinations of subgroups in the sensitive and control features.If a particular combination of subgroups was not present in the dataset (likely to occur as more sensitive and control features are specified), then the corresponding entry will be NaN.
- property by_group_ci: list[Series] | list[DataFrame]#
Return the confidence intervals for the metrics, evaluated on each subgroup.
When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list, with each element having the same type as that returned by the
MetricFrame.by_groupproperty. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.
- property control_levels: list[str] | None#
Return a list of feature names which are produced by control features.
If control features are present, then the rows of the
by_groupproperty have apandas.MultiIndexindex. This property identifies which elements of that index are control features.- Returns:
- List[
str] orNone List of names, which can be used in calls to
pandas.DataFrame.groupby()etc.
- List[
- property overall: Any | Series | DataFrame#
Return the underlying metrics evaluated on the whole dataset.
Read more in the User Guide.
- Returns:
- typing.Any or
pandas.Seriesorpandas.DataFrame The exact type varies based on whether control featuers were provided and how the metric functions were specified.
Metrics
Control Features
Result Type
Callable
None
Return type of callable
Callable
Provided
Series, indexed by the subgroups of the conditional feature(s)
dict
None
Series, indexed by the metric names
dict
Provided
DataFrame. Columns are metric names, rows are subgroups of conditional feature(s)
The distinction applies even if the dictionary contains a single metric function. This is to allow for a consistent interface when calling programmatically, while also reducing typing for those using Fairlearn interactively.
- typing.Any or
- property overall_ci: list[Any | Series | DataFrame]#
Return the underlying bootstrapped metrics evaluated on the whole dataset.
When bootstrapping has been activated (by n_boot and ci_quantiles in the constructor), this property will be available. The contents will be a list of the same underlying type as that returned by
MetricFrame.overallproperty. The elements of the list are indexed by the ci_quantiles array supplied to the constructor.
- property sensitive_levels: list[str]#
Return a list of the feature names which are produced by sensitive features.
In cases where the
by_groupproperty has apandas.MultiIndexindex, this identifies which elements of the index are sensitive features.Read more in the User Guide.
- Returns:
- List[
str] List of names, which can be used in calls to
pandas.DataFrame.groupby()etc.
- List[
Gallery examples#

Basics & Model Specification of AdversarialFairness